Video compression is the process of converting digital video into a format that takes up less capacity when it is stored or transmitted. H.264 is a method and format for video compression. An encoder converts video into a compressed format and a decoder converts compressed video back into an uncompressed format. In a typical application such as remote surveillance, video from a camera is encoded or compressed using H.264 to produce an H.264 bitstream. This is sent across a network to a decoder which reconstructs a version of the source video.
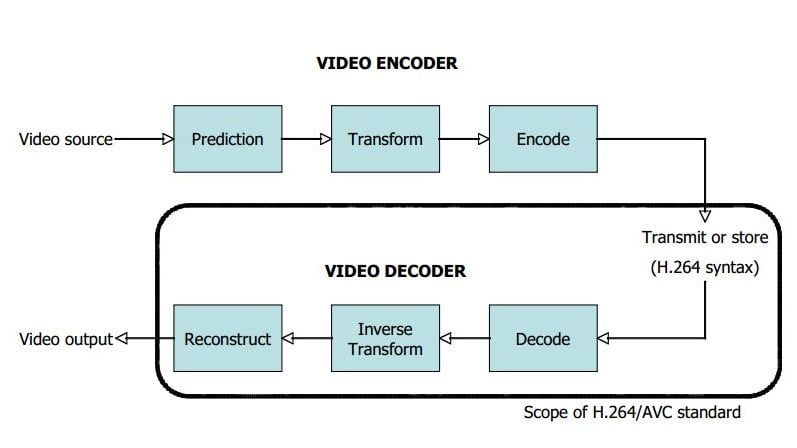
We will discuss about basics of H.264 video compression format. We will also cover typical video encoder and video decoder block diagram.
Typical Video Encoder
In the encoder, a prediction macroblock is generated and subtracted from the current macroblock to form a residual macroblock. This residual macroblock is transformed, quantized and encoded. In parallel, the quantized data are re-scaled and inverse transformed. It is then added to the prediction macroblock to reconstruct a frame which is stored for later predictions.
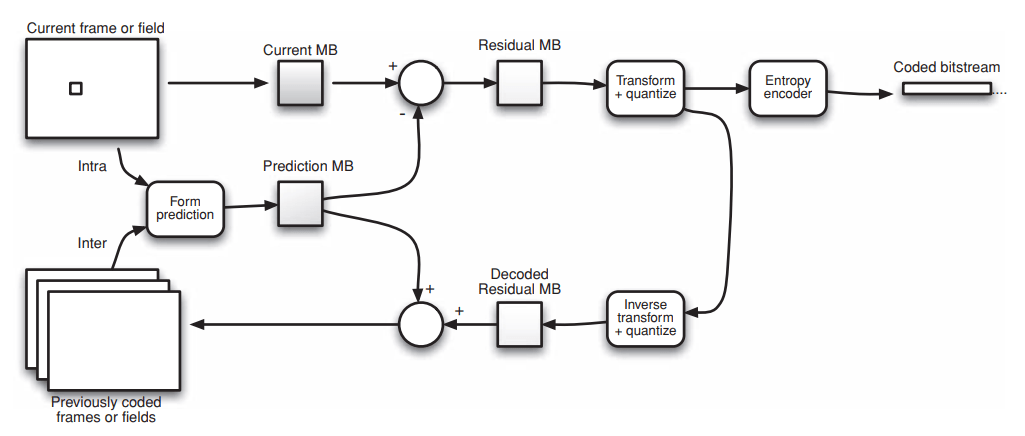
In the above figure MB stands for Macroblock.
Prediction
From prediction in the above figure, denotes the prediction of the current macroblock. A prediction of the current macroblock is based on previously-coded data. Either from the current frame (intra prediction) or from other frames that have already been coded (inter prediction). The values of the previously-coded neighboring pixels are extrapolated to form a prediction of the current macroblock.
Intra prediction uses 16 × 16 and 4 × 4 block sizes to predict the macroblock from surrounding, previously coded pixels within the same frame. Inter prediction uses a range of block sizes from 16 × 16 down to 4 × 4 to predict pixels in the current frame from similar regions in previously coded frames. These previously coded frames may occur before or after the current frame in display order. In the below figure, macroblock 1 (MB1) in the current frame is predicted from a 16 × 16 region in the most recent ‘past’ frame. MB2 is predicted from two previously coded frames.
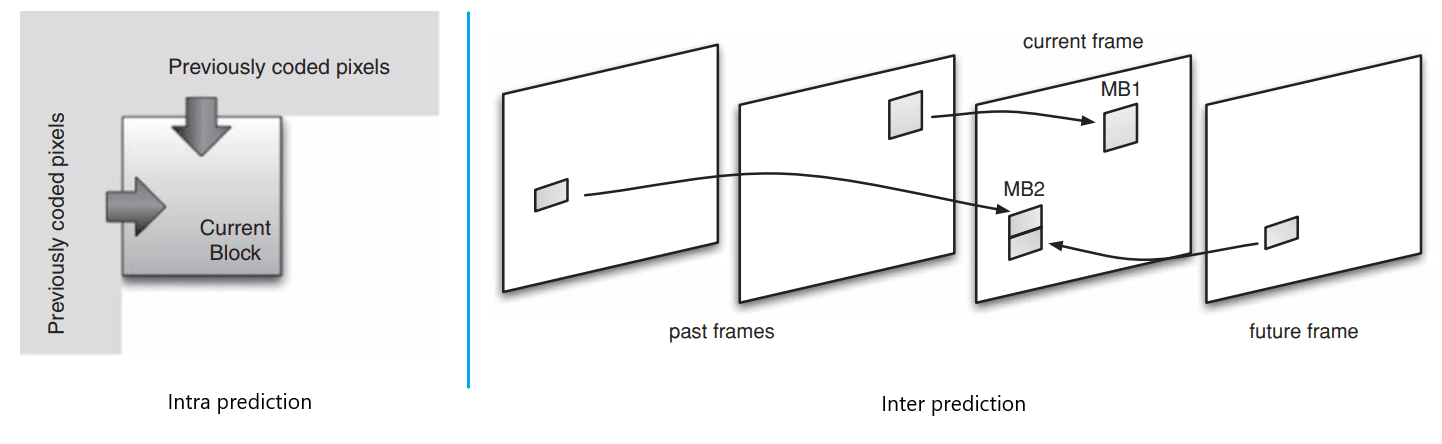
The encoder subtracts the prediction from the current macroblock to form a residual.
Transform and Quantization
A block of residual samples is transformed using a 4 × 4 or 8 × 8 integer transform (Discrete Cosine Transform). The transform outputs a set of coefficients, each of which is a weighting value for a standard basis pattern (orthogonal basis functions). When combined, the weighted basis patterns re-create the block of residual samples.
A good transform is able to decorrelate the input video samples and concentrate most of the video information (or energy) using a small number of transform coefficients. In this way, many coefficients can be discarded, thus leading to compression gains. The transform should be invertible and computationally efficient. In addition, the basis functions of a good transform should produce smoother and perceptually pleasant reconstructed samples. Many video coding standards employ a block transform of the residuals. Intracoded blocks and residuals are commonly processed in N × N blocks (N is usually 4, 8, 16, 32) by a two-dimensional (2D) discrete transform.
The use of smaller transform sizes such as 4 × 4 leads to several benefits as intra and intercoding methods improve. This is because the residual contains less spatial correlation, which implies the transform is less effective in statistical decorrelation. Smaller transforms also generates less noise or ringing artifacts around the block edges and require fewer computations. The 2D transformation is typically achieved by applying one-dimensional (1D) transforms in the horizontal (i.e., row-wise) and vertical (i.e., column-wise) directions.
The output of the transform is quantized, i.e. each coefficient is divided by an integer value. Quantization reduces the precision of the transform coefficients according to a quantization parameter (QP). Setting QP to a high value means that more coefficients are set to zero, resulting in high compression at the expense of poor decoded image quality. Setting QP to a low value means that more non-zero coefficients remain after quantization, resulting in better image quality at the decoder but also in lower compression.
Although transform coefficients take up the most bandwidth, they can be compressed more easily because the information is statistically concentrated in just a few coefficients. This process is called transform coding, which reduces the inherent spatial redundancy between adjacent samples.
Like the quantization steps, an unequal or nonuniform number of bits can be assigned to the quantized values to enable more efficient entropy encoding using variable length codes (VLCs). For example, shorter codes can be assigned to more likely quantized values and the probability of each value is determined based on the values used for coding surrounding blocks.
Entropy Encoding
Entropy coding is a lossless or reversible process that achieves additional compression by coding the syntax elements (e.g., transform coefficients, prediction modes, MVs) into the final output file. As such, it does not modify the quantization level. VLCs such as Huffman, Golomb, or arithmetic codes are statistical codes that have been widely used.
The video coding process produces a number of values that must be encoded to form the compressed bitstream. These values include:
- Information to enable the decoder to re-create the prediction
- Quantized transform coefficients
- Information about the structure of the compressed data and the compression tools used during encoding
- Information about the complete video sequence.
These values and parameters, syntax elements, are converted into binary codes using variable length coding and/or arithmetic coding. Each of these encoding methods produces an efficient, compact binary representation of the information. The encoded bitstream can then be stored and/or transmitted.
Variable Length Codes
VLCs may assign shorter code word to frequent bit strings and longer code word to less frequent bit strings, thus leading to unbalanced code trees with unequal probabilities. This is in contrast to fixed-length codes that lead to optimal balanced trees when the bit strings are equally probable. Contiguous bit strings can be represented as a single value and a multiplier. For example, a bitstream of 0000000000000000111111110000000 00000000000000000 can be represented as 0 × 16, 1 × 8, 0 × 24 or 0 [10000], 1 [01000], 0 [11000]. Thus, the original 48 bits can be transmitted using only 18 bits.
Typical Video Decoder
In the decoder, a macroblock is decoded, re-scaled and inverse transformed to form a decoded residual macroblock. The decoder generates the same prediction that was created at the encoder. It adds this to the residual to produce a decoded macroblock.
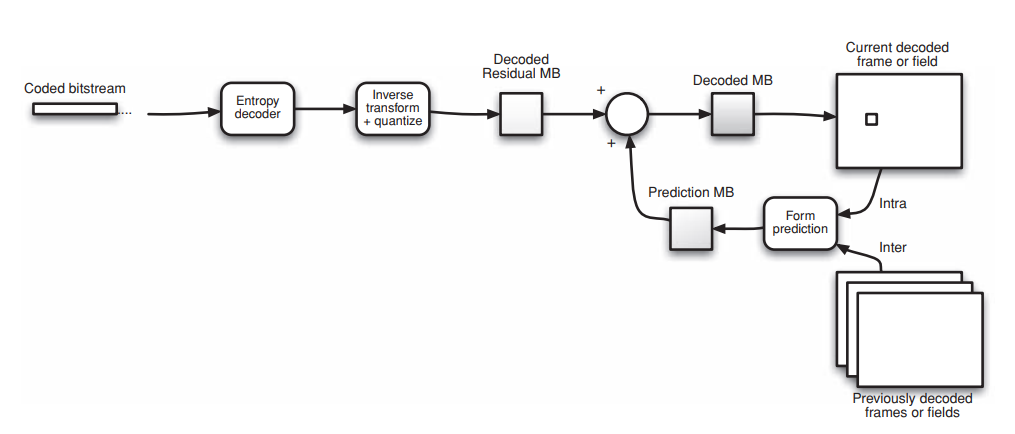
Bitstream decoding
A video decoder receives the compressed H.264 bitstream, decodes each of the syntax elements and extracts the information described above, i.e.
- Quantized transform coefficients
- Prediction information
- Information about the complete video sequence.
This information is then used to reverse the coding process and recreate a sequence of video images.
Rescaling and inverse transform
The quantized transform coefficients are re-scaled. Each coefficient is multiplied by an integer value to restore its original scale. The re-scaled coefficients are similar but not identical to the originals. In the below figure, each quantized coefficient is multiplied by a QP or step size of 8.
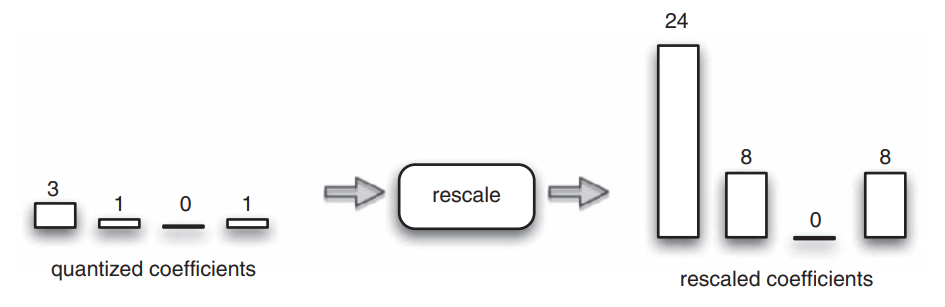
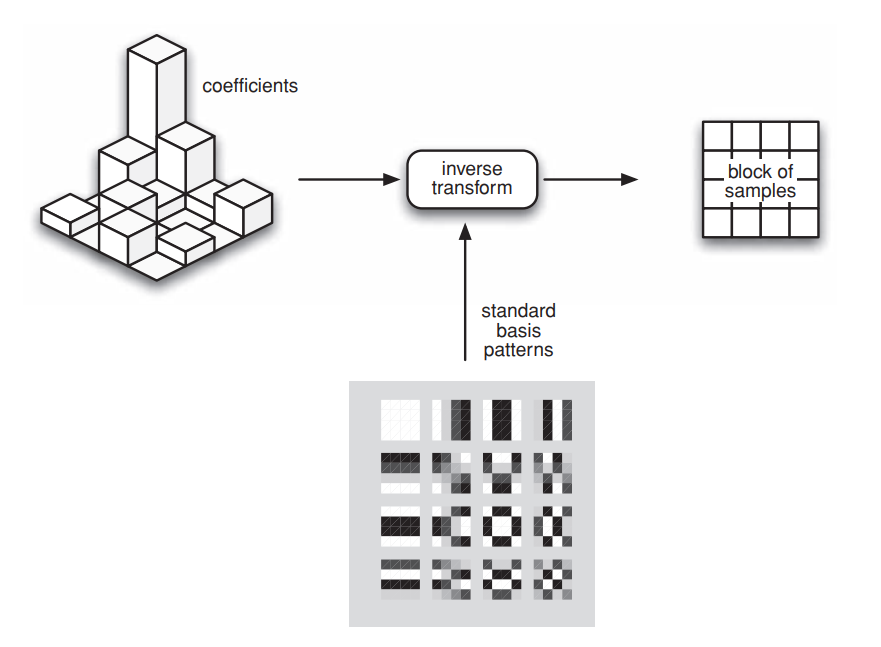
An inverse transform combines the standard basis patterns, weighted by the re-scaled coefficients, to re-create each block of residual data. Below figure shows how the inverse DCT creates an image block by weighting each basis pattern according to a coefficient value and combining the weighted basis patterns. These blocks are combined together to form a residual macroblock. In the below figure, the quantized coefficients are rescaled using a quantization step size and inverse transformed. The reconstructed blocks are similar but not identical to the original block. The difference or loss is due to the forward quantization process. A larger quantization step size tends to produce a larger difference between original and reconstructed blocks.
Reconstruction
For each macroblock, the decoder forms an identical prediction to the one created by the encoder using inter prediction from previously-decoded frames or intra prediction from previously-decoded samples in the current frame. The decoder adds the prediction to the decoded residual to reconstruct a decoded macroblock which can then be displayed as part of a video frame.