We design an image sharing service like Flickr. Besides sharing files/images, users can also append metadata to files and other users, such as access control, comments, or favorites.
Functional Requirements
Let’s discuss user stories with the interviewer and scribble them down:
- A user can view photos shared by others. We refer to this user as a viewer.
- Our app should generate and display thumbnails of 50 px width. A user should view multiple photos in a grid and can select one at a time to view the full-resolution version.
- A user can upload photos. We refer to this user as a sharer.
- A sharer can set access control on their photos.
- A photo has predefined metadata fields, which have values provided by the sharer. Example fields are location or tags.
- An example of dynamic metadata is the list of viewers who have read access to the file. This metadata is dynamic because it can be changed.
- Users can comment on photos. A sharer can toggle commenting on and off. A user can be notified of new comments.
- A user can favorite a photo.
- A user can search on photo titles and descriptions.
Non-functional Requirements
Here are some questions we may discuss on non-functional requirements:
- Our system must be scalable. It should serve one billion users distributed across the world. We expect heavy traffic. Assume 1% of our users (10 million) upload 10 high-resolution (10 MB) images daily. This works out to 1 PB of uploads daily. The average traffic is over 1 GB/second, but we should expect traffic spikes, so we should plan for 10 GB/second.
- Photos can take a few minutes to be available to our entire user base. We can trade off certain non-functional characteristics for lower cost, such as consistency or latency, and likewise for comments. Eventual consistency is acceptable.
- Privacy settings must be effective sooner. A deleted photo does not have to be erased from all our storage within a few minutes; a few hours is permissible. However, it should be inaccessible to all users within a few minutes.
- High-resolution photos require high network speeds, which may be expensive. So user should only be able to download one high-resolution photo at a time, but multiple low-resolution thumbnails can be downloaded simultaneously. When a user is uploading files, we can upload them one at a time.
- High availability, such as five 9s (99.999) availability. There should be no outages that prevent users from downloading or uploading photos.
- High performance and low latency. High performance is not needed for uploads.
The server can generate a thumbnail from the full-resolution image each time a client requests a thumbnail. This will be scalable if it was computationally inexpensive to generate a thumbnail. However, a full-resolution image file is tens of MB in size. A viewer will usually request a grid of >10 thumbnails in a single request. Assuming a full-resolution image is 10 MB (it can be much bigger), this means the server will need to process >100 MB of data in much less than one second. Moreover, the viewer may make many such requests within a few seconds as they scroll through thumbnails. So this approach will be prohibitively expensive. The only scalable approach is to generate and store a thumbnail just after the file is uploaded and serve these thumbnails when a viewer requests them. Each thumbnail will only be a few KBs in size, so storage costs are low. We can also cache both thumbnails and full-resolution image files on the client.
High-level architecture
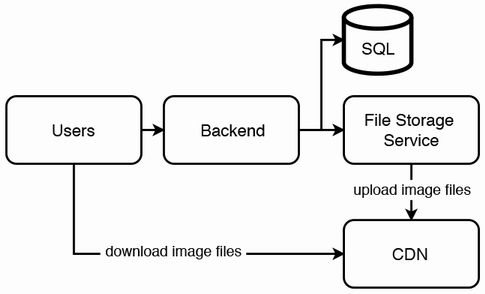
Organizing Files on the CDN
A directory hierarchy can be user > album > resolution > file in CDN. Each user has their own CDN directory. We may allow a user to create albums, where each album has 0 or more photos. Each photo can only belong to one album.
An album directory can store the several files of the image in various resolutions, each in its own directory, and a JSON image metadata file. For example, a directory “original” may contain an originally-uploaded file “swans.png,” and a directory “thumbnail” may contain the generated thumbnail “swans_thumbnail.png.”
Uploading a photo
Generating thumbnails on the client saves computational resources on our backend, and the thumbnail is small, so it contributes little to network traffic. A 100 px thumbnail is about 40 KB, a negligible addition to a high-resolution photo, which may be a few MB to 10s of MB in size.
Before the upload process, the client may check if the thumbnail has already been uploaded to the CDN. During the upload process, the following steps occur:
- Generate the thumbnail.
- Place both files into a folder and then compress it with an encoding like Gzip or Brotli. Compression of a few MB to 10s of MB saves significant network traffic, but our backend will expend CPU and memory resources to uncompress the directory.
- Use a POST request to upload the compressed file to our CDN directory.
- On the CDN, create directories as necessary, unzip the compressed file, and write the files to disk. Replicate it to the other data centers.

We have no control over many of these situations that may occur on a client. We may overlook failure scenarios during implementation and testing, and debugging is more difficult because it is harder to replicate the situation that occurred on a client’s device than on a server that we own and have admin access to.
Generating on a server requires more hardware resources, as well as engineering effort to create and maintain this backend service, but the service can be created with the same language and tools as other services. We may decide that the costs of the former outweigh the latter. Steps for generating thumbnails on the backend:
- Before uploading the file, check if the file has been uploaded before. This prevents costly and unnecessary duplicate uploads.
- Upload the file to the file storage service and CDN.
- Generate the thumbnail and upload it to the file storage service and CDN.
The detailed steps are as follows. The step numbers are labeled on both figures:
- The user first hashes the image and then makes a GET request to the backend check if the image has already been uploaded. This may happen because the user successfully uploaded the image in a previous request, but the connection failed while the file storage service or backend was returning success, so the user may be retrying the upload.
- Our backend forwards the request to the file storage service.
- Our file storage service returns a response that indicates if the file had already been successfully uploaded.
- Our backend returns this response to the user.
- This step depends on whether the file has already been successfully uploaded.
- If this file has not been successfully uploaded before, the user uploads this file to our file storage service via the backend. (The user may compress the file before uploading it.)
- Alternatively, if the file has already been successfully uploaded, our backend can produce a thumbnail generation event to our Kafka topic. We can skip to step 8.
- Our file storage service writes the file to the object storage service.
- After successfully writing the file, our file storage service produces an event to our CDN Kafka topic and then returns a success response to the user via the backend.
- Our file storage service consumes the event from step 6, which contains the image hash.
- Similar to step 1, our file storage service makes a request to the CDN with the image hash to determine whether the image had already been uploaded to the CDN. This could have happened if a file storage service host had uploaded the image file to the CDN before, but then failed before it wrote the relevant checkpoint to the CDN topic.
- Our file storage service uploads the file to the CDN. This is done asynchronously and independently of the upload to our file storage service, so our user experience is unaffected if upload to the CDN is slow.
- Our file storage service produces a thumbnail generation event that contains the file ID to our thumbnail generation Kafka topic and receives a success response from our Kafka service.
- Our backend returns a success response to the user that the latter’s image file is successfully uploaded. It returns this response only after producing the thumbnail generation event to ensure that this event is produced, which is necessary to ensure that the thumbnail generation will occur. If producing the event to Kafka fails, the user will receive a 504 Timeout response.
- Our thumbnail generation service consumes the event from Kafka to begin thumbnail generation.
- The thumbnail generation service fetches the file from the file storage service, generates the thumbnails, and writes the output thumbnails to the object storage service via the file storage service.
- The thumbnail generation service writes a ThumbnailCdnRequest to the CDN topic to request the file storage service to write the thumbnails to the CDN.
- The file storage service consumes this event from the CDN topic and fetches the thumbnail from the object storage service.
- The file storage service writes the thumbnail to the CDN. The CDN returns the file’s key.
- The file storage service inserts this key to the SQL table (if the key does not already exist) that holds the mapping of user ID to keys. Note that steps 16–18 are blocking. If the file storage service host experiences an outage during this insert step, its replacement host will rerun from step 16. The thumbnail size is only a few KB, so the computational resources and network overhead of this retry are trivial.
- Depending on how soon our CDN can serve these (high-resolution and thumbnail) image files, we can delete these files from our file storage service immediately, or we can implement a periodic batch ETL job to delete files that were created an hour ago. Such a job may also query the CDN to ensure the files have been replicated to various data centers, before deleting them from our file storage service, but that may be overengineering. Our file storage service may retain the file hashes, so it can respond to requests to check if the file had been uploaded before. We may implement a batch ETL job to delete hashes that were created more than one hour ago.

Our client can first try to generate the thumbnail. If it fails, our server can generate it. With this approach, our initial implementations of client-side generation do not have to consider all possible failure scenarios, and we can choose to iteratively improve our client-side generation. This approach is more complex and costly than just server-side generation, but may be cheaper and easier than even just client-side generation because the client-side generation has the server-side generation to act as a failover, so client-side bugs and crashes will be less costly.
Downloading images
The images and thumbnails have been uploaded to the CDN, so they are ready for viewers. A request from a viewer for a sharer’s thumbnails is processed as follows:
- Query the Share table for the list of sharers who allow the viewer to view the former’s images.
- Query the Image table to obtain all CdnPath values of thumbnail resolutions images of the user. Return the CdnPath values and a temporary OAuth2 token to read from the CDN.
- The client can then download the thumbnails from the CDN. To ensure that the client is authorized to download the requested files, our CDN can use the token authorization mechanism.
Dynamic content may be updated or deleted, so we store them on SQL rather than on the CDN. This includes photo comments, user profile information, and user settings. We can use a Redis cache for popular thumbnails and popular full-resolution images. When a viewer favorites an image, we can take advantage of the immutable nature of the images to cache both the thumbnails and the full-resolution image on the client if it has sufficient storage space. Then a viewer’s request to view their grid of favorite images will not consume any server resources and will also be instantaneous.