Autocomplete is a useful question to test a candidate’s ability to design a distributed system that continuously ingests and processes large amounts of data into a small (few MBs) data structure that users can query for a specific purpose. An autocomplete system obtains its data from strings submitted by up to billions of users and then processes this data into a weighted trie. When a user types in a string, the weighted trie provides them with autocomplete suggestions. We can also add personalization and machine learning elements to our autocomplete system.
Possible uses of autocomplete
We first discuss and clarify the intended use cases of this system to ensure we determine the appropriate requirements. Possible uses of autocomplete include:
- Complements a search service. While a user enters a search query, the autocomplete service returns a list of autocomplete suggestions with each keystroke. If the user selects a suggestion, the search service accepts it and returns a list of results.
- A word processor may provide autocomplete suggestions. When a user begins typing a word, they may be provided autocomplete suggestions for common words that begin with the user’s currently entered prefix. Using a technique called fuzzy matching, the autocomplete feature can also be a spellcheck feature that suggests words with prefixes that closely match but are not identical to the user’s currently entered prefix.
- An integrated development environment (IDE) (for coding) may have an autocomplete feature. The autocomplete feature can record variable names or constant values within the project directory and provide them as autocomplete suggestions whenever the user declares a variable or constant. Exact matches are required (no fuzzy matching).
An autocomplete service for each of these use cases will have different data sources and architecture.
Functional Requirements
We can first clarify some details of our scope:
- Is this autocomplete meant for a general search service or for other use cases like a word processor or IDE?
- Is this only for English?
- Is the autocomplete on words or sentences?
- Is there a minimum number of characters that should be entered before suggestions are displayed?
- Is there a minimum length for suggestions? It’s not useful for a user to get suggestions for 4 or 5-letter words after typing in 3 characters, since those are just 1 or 2 more letters.
- Should we consider numbers or special characters, or just letters?
- How many autocomplete suggestions should be shown at a time, and in what order?
We need to consider if the autocomplete suggestions should be based only on the user’s current input or on their search history and other data sources.
- Limiting the suggestions to a set of words implies that we need to process users’ submitted search strings. If the output of this processing is an index from which autocomplete suggestions are obtained, does previously processed data need to be reprocessed to include these manually added and removed words/phrases?
- What is the data source for suggestions? Is it just the previously submitted queries, or are there other data sources, such as user demographics?
- Should it display suggestions based on all user data or the current user data (i.e., personalized autocomplete)?
- What period should be used for suggestions?
Let’s first consider all time and then maybe consider removing data older than a year. We can use a cutoff date, such as not considering data before January 1 of last year.
Non-functional requirements
After discussing the functional requirements, we can have a similar Q&A to discuss the non-functional requirements. This may include a discussion of possible tradeoffs such as availability versus performance:
- It should be scalable so it can be used by a global user base.
- High availability is not needed. This is not a critical feature, so fault-tolerance can be traded off.
- High performance and throughput are necessary. Users must see autocomplete suggestions within half a second.
- Consistency is not required. We can allow our suggestions to be hours out of date; new user searches do not need to immediately update the suggestions.
- For privacy and security, no authorization or authentication is needed to use autocomplete, but user data should be kept private.
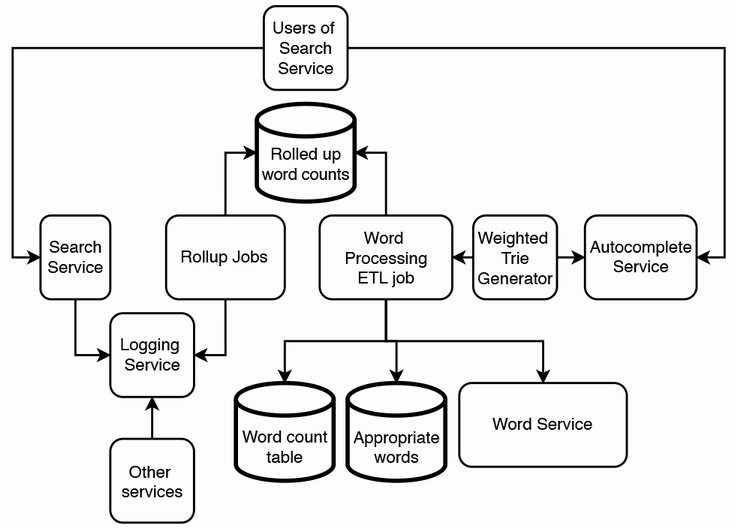
High-level architecture
Our Autocomplete System is not a single service but a system where users only query one service (the autocomplete service) and do not directly interact with the rest of the system. The rest of the system serves to collect users’ search strings and periodically generate and deliver a weighted trie to our autocomplete service.
The shared logging service is the raw data source from which our autocomplete service derives the autocomplete suggestions that it provides to its users. Search service users send their queries to the search service, which logs them to the logging service. Other services also log to this shared logging service. The autocomplete service may query the logging service for just the search service logs or other services’ logs, too, if we find those useful to improve our autocomplete suggestions. Autocomplete suggestions are generated using a weighted trie,
Our word count pipeline may have the following tasks/steps
- Fetch the relevant logs from the search topic of the logging service (and maybe other topics) and place them in a temporary storage.
- Split the search strings into words.
- Filter out inappropriate words.
- Count the words and write to a word count table.
- Filter for appropriate words and record popular unknown words.
- Generate the weighted trie from the word count table.
- Send the weighted trie to our backend hosts.
We split the search strings by whitespace with the split function. (We may also need to consider common problems like the users omitting spaces (e.g., “HelloWorld”) or using other separators like a period, dash, or comma.
Filter Inappropriate Words
Next filter the inappropriate words. We will consider these two parts in filtering for appropriate words or filtering out inappropriate words:
- Managing our lists of appropriate and inappropriate words.
- Filtering our list of search words against our lists of appropriate and inappropriate words.
Our words service has API endpoints to return sorted lists of appropriate or inappropriate words. These lists will be at most a few MB and are sorted to allow binary search. Their small size means that any host that fetches the lists can cache them in memory in case the words service is unavailable. The SQL tables for appropriate and inappropriate words may contain a string column for words, and other columns that provide information such as the timestamp when the word was added to the table, the user who added this word, and an optional string column for notes such as why the word was appropriate or inappropriate. Our words service provides a UI for admin users to view the lists of appropriate and inappropriate words and manually add or remove words, all of which are API endpoints. Our backend may also provide endpoints to filter words by category or to search for words
Count Words
A final processing step before we count the words is to correct misspellings in users’ search words. We can code a function that accepts a string, uses a library with a fuzzy matching algorithm to correct possible misspelling, and returns either the original string or fuzzy-matched string. (Fuzzy matching, also called approximate string matching, is the technique of finding strings that match a pattern approximately.
We are now ready to count the words. This can be a straightforward MapReduce operation, or we can use an algorithm like count-min sketch. We map the words in the input HDFS file to (String, Int) pairs called counts, sort by descending order of counts.
After counting the words in the previous step, we may find new popular words in the top 100, which were previously unknown to us. In this stage, we write these words to the Words Service, which can write them to a SQL unknown_words table.
Generate weighted TRIE
We now have the list of top appropriate words to construct our weighted trie. This list is only a few MB, so the weighted trie can be generated on a single host. Now serialize the weighted trie to JSON. The trie is a few MB in size, which may be too large to be downloaded to the client each time the search bar is displayed to the user but is small enough to replicate to all hosts. We can write the trie to a shared object store such as AWS S3 or a document database such as MongoDB or Amazon DocumentDB. Our backend hosts can be configured to query the object store daily and fetch the updated JSON string.
If a shared object is large (e.g., gigabytes), we should consider placing it in a CDN. Another advantage of this small trie is that a user can download the entire trie when they load our search app, so the trie lookup is client-side rather than server-side.