Rate limiting defines the rate at which consumers can make requests to API endpoints. Rate limiting prevents inadvertent or malicious overuse by clients, especially bots. Examples of inadvertent overuse include the following:
- Our client is another web service that experienced a (legitimate or malicious) traffic spike.
- The developers of that service decided to run a load test on their production environment.
Such inadvertent overuse causes a “noisy neighbor” problem, where a client utilizes too much resource on our service, so our other clients will experience higher latency or higher rate of failed requests. Rate limiting can prevent some of the malicious attacks. Malicious attacks include the following.
- Denial-of-service (DoS) or distributed denial-of-service (DDoS) attacks — DoS floods a target with requests, so normal traffic cannot be processed. DoS uses a single machine, while DDoS is the use of multiple machines for the attack.
- Brute force attack — A brute force attack is repeated trial and error to find sensitive data, such as cracking passwords, encryption keys, API keys, and SSH login credentials.
- Web scraping — Web scraping uses bots to make GET requests to many web pages of a web application to obtain a large amount of data. An example is scraping Amazon product pages for prices and product reviews.
Rate limiting can be implemented as a library or as a separate service called by a frontend, API gateway, or service mesh. We implement it as a service to gain the advantages of functional partitioning. Below figure illustrates a rate limiter design.
Functional requirements
Our rate-limiting service is a shared service, and our users are mainly services that are used by parties external to the company and not by internal users such as employees. We refer to such services as “user services.” A user should be able to set a maximum request rate over which further requests from the same requestor will be delayed or rejected. We can assume the interval can be 10 seconds or 60 seconds. We can set a maximum of 10 requests in 10 seconds. Other functional requirements are as follows:
- We assume that each user service must rate limit its requestors across its hosts, but we do not need to rate limit the same users across services. Rate limiting is independent on each user service.
- A user can set multiple rate limits, one per endpoint. We want our rate limiter to be a cheap and scalable service that is easy to understand and use.
- Our users should be able to view which users were rate limited and the timestamps these rate limiting events began and ended. We provide an endpoint for this.
- We can discuss with the interviewer whether we should log every request because we will need a large amount of storage to do so, which is expensive. We will assume that this is needed and discuss techniques to save storage to reduce cost.
- We should log the rate-limited requestors for manual follow-up and analytics. This is especially required for suspected attacks.
Non-functional requirements
Rate limiting is a basic functionality required by virtually any service. It must be scalable, have high performance, be as simple as possible, secure, and private. Rate limiting is not essential to a service’s availability, so we can trade off high availability and fault-tolerance. Accuracy and consistency are fairly important but not stringent.
Scalability
Our service should be scalable to billions of daily requests that query whether a particular requestor should be rate limited. Requests to change rate limits will only be manually made by internal users in our organization, so we do not need to expose this capability to external users.
Assume we need to store up 100 requests per user at any moment. Only the user IDs and a queue of 100 timestamps per user need to be recorded; each is 64 bits. Our rate limiter is a shared service, so we will need to associate requests with the service that is being rate limited. Let’s assume that there are 100 service that need rate limiting. A rate limiter usually should only need to store data for 10 seconds because it makes a rate limiting decision based on the user’s request rate for the last 10 seconds. Let’s make a conservative worst-case estimate of 10 million users. Our overall storage requirement is 100 (no. of request per user) * 64 (user id) * 101 (no. of service) * 10M (no. of user) = 808 GB.
Performance
When another service receives a request from its user, it makes a request to our rate limiting service to determine if the user request should be rate-limited. The rate limiter request is blocking; the other service cannot respond to its user before the rate limiter request is completed. The rate limiter request’s response time adds to the user request’s response time. So, our service needs very low latency. The decision to rate-limit or not rate-limit the user request must be quick.
Availability and fault-tolerance
We may not require high availability or fault-tolerance. If our service has less than three nines availability and is down for an average of a few minutes daily, user services can simply process all requests during that time and not impose rate limiting. Moreover, the cost increases with availability. Providing 99.9% availability is fairly cheap, while 99.99999% may be prohibitively expensive.
As discussed later in this chapter, we can design our service to use a simple highly available cache to cache the IP addresses of excessive clients. If the rate-limiting service identified excessive clients just prior to the outage, this cache can continue to serve rate-limiter requests during the outage, so these excessive clients will continue to be rate limited. It is statistically unlikely that an excessive client will occur during the few minutes the rate limiting service has an outage. If it does occur, we can use other techniques such as firewalls to prevent a service outage, at the cost of a negative user experience during these few minutes.
Accuracy
To prevent poor user experience, we should not erroneously identify excessive clients and rate limit them. In case of doubt, we should not rate limit the user. The rate limit value itself does not need to be precise. For example, if the limit is 10 requests in 10 seconds, it is acceptable to occasionally rate limit a user at 8 or 12 requests in 10 seconds.
Consistency
The previous discussion on accuracy leads us to the related discussion on consistency. We do not need strong consistency for any of our use cases. When a user service updates a rate limit, this new rate limit need not immediately apply to new requests; a few seconds of inconsistency may be acceptable. Eventual consistency is also acceptable for viewing logged events such as which users were rate-limited or performing analytics on these logs. Eventual rather than strong consistency will allow a simpler and cheaper design.
High-level architecture
Below illustrates our high-level architecture considering these requirements and stories. We need the following:
- A database with fast reads and writes for counts. The schema will be simple; it is unlikely to be much more complex than (user ID, service ID). We can use an in-memory database like Redis.
- A service where rules can be defined and retrieved, which we call the Rules service.
- A service that makes requests to the Rules service and the Redis database, which we can call the Backend service.
The two services are separate because requests to the Rules service for adding or modifying rules should not interfere with requests to the rate limiter that determine if a request should be rate limited.
When a client makes a request to our rate-limiting service, this request initially goes through the frontend or service mesh. If the frontend’s security mechanisms allow the request, the request goes to the backend, where the following steps occur:
- Get the service’s rate limit from the Rules service. This can be cached for lower latency and lower request volume to the Rules service.
- Determine the service’s current request rate, including this request.
- Return a response that indicates if the request should be rate-limited.
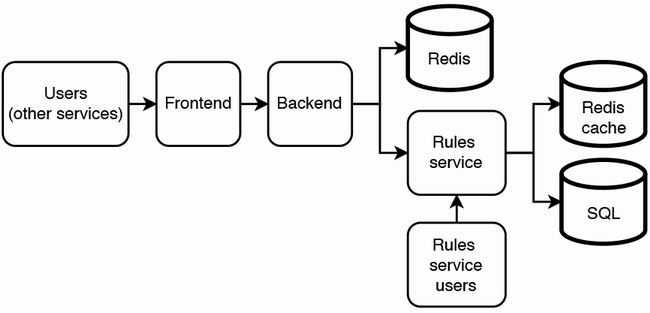
Rules service has users from two different services (Backend and Rules service users) with very different request volumes, one of which (Rules service users) does all the writes. The Rules service users may make API requests to the Rules service via a browser app. We do not expect rules to change often, we can add a Redis cache to the Rules service to improve its read performance even further. As soon as a user exceeds its rate limit, we can cache its ID along with an expiry time where a user should no longer be rate-limited. Then our backend need not query the Rules service to deny a user’s request.